Felipe Bossolani
Founder da MeuPortfolio (vendida para a Warren) e co-founder de uma empresa adquirida pela Britech. Hoje CPTO da Warren. Há mais de 20 anos construindo produtos, plataformas e times de alta performance, com foco em engenharia sólida, decisões difíceis e IA como alavanca estratégica.
De arquivos locais para cloud-native: refatorando o pipeline de dados da B3 com Cloudflare R2
by Felipe Bossolani
Série construindo em público - episódio 1
Como utilizamos Claude para arquitetar e implementar uma infraestrutura de dados de nível profissional
Resumo executivo
Refatoramos nosso pipeline de dados do mercado financeiro brasileiro, migrando de armazenamento local para Cloudflare R2, utilizando Claude para gerar um PRD completo e guiar a implementação. Este artigo cobre as decisões arquiteturais, o fluxo de desenvolvimento assistido, e as lições aprendidas ao evoluir um sistema funcional para infraestrutura de produção.
Stack tecnológica: Python, Cloudflare R2, MinIO (desenvolvimento local), PostgreSQL, Arquitetura orientada a eventos
Cronograma: De local para cloud-native em uma semana
Linhas de código alteradas: Aproximadamente 500 (majoritariamente adições)
O problema: arquivos locais não escalam
Nosso pipeline de ingestão de dados da B3 funcionava perfeitamente… no meu laptop.
O fluxo original era simples:
Site B3 → Download CSV → Salvar Localmente → Processar → PostgreSQL
Funcionava, mas tinha problemas críticos:
- Sem redundância - Se minha VPS travasse, perderíamos os dados brutos
- Sem trilha de auditoria - Quais arquivos processamos? Quando?
- Sem colaboração - Difícil compartilhar dados com membros da equipe
- Triggers manuais - Eu tinha que lembrar de executar o script
- Problemas de escala - O que acontece quando adicionamos dados ANBIMA, CVM?
O pipeline era funcional, mas não estava pronto para produção.
A decisão: por que Cloudflare R2?
Ao avaliar soluções de object storage, comparamos AWS S3, Google Cloud Storage e Cloudflare R2.
O que nos convenceu no R2:
1. Zero taxas de egress (o diferencial)
A maioria dos provedores de nuvem cobra pesado quando você faz download de dados. Com nosso caso de uso (downloads diários para processamento), isso aumenta rápido:
Comparação de custos estimados (1TB armazenado + 10TB transferência/mês):
| Recurso | AWS S3 (Standard) | Google Cloud Storage | Cloudflare R2 |
|---|---|---|---|
| Armazenamento (1TB) | ~$23.00 | ~$20.00 | $15.00 |
| Egress (10TB) | ~$900.00 | ~$1,200.00 | $0.00 |
| Total mensal | ~$923.00 | ~$1,220.00 | ~$15.00 |
Valores aproximados baseados nas calculadoras oficiais dos provedores.
2. API compatível com S3
Estamos usando boto3 do Python - a mesma biblioteca usada para AWS S3. A migração foi apenas trocar a URL do endpoint. Sem necessidade de reescrever código.
3. Notificações de eventos nativas
R2 pode disparar eventos quando arquivos são enviados, possibilitando arquitetura verdadeiramente orientada a eventos sem polling.
4. Estratégia multi-cloud
R2 atua como armazenamento vendor-neutral. Podemos processar dados em qualquer lugar sem ficar presos ao ecossistema de um único provedor de nuvem.
A abordagem assistida: Claude como arquiteto técnico
Aqui as coisas ficam interessantes. Em vez de mergulhar direto no código, usamos Claude para criar primeiro um Product Requirements Document (PRD) completo.
Por que começar com um PRD?
Abordagem tradicional:
- Ideia
- Código
- Debug
- Percebe que esqueceu algo
- Refatorar
- Mais bugs
Abordagem assistida:
- Ideia
- PRD gerado
- Revisão
- Implementar task por task
- Commits limpos
A conversa com Claude
Nossa conversa evoluiu naturalmente:
Eu: “Preciso migrar de armazenamento local para Cloudflare R2”
Claude: Explica os básicos do R2, preços, diferenças do S3
Eu: “Me mostre como criar o bucket”
Claude: Fornece guia passo a passo com screenshots
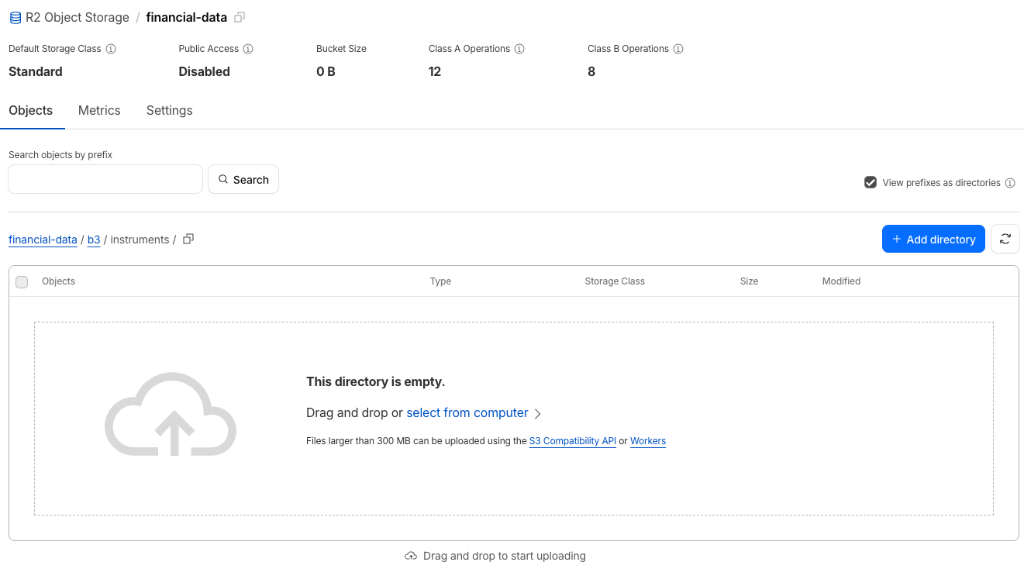 Interface de gerenciamento de buckets no Cloudflare R2.
Interface de gerenciamento de buckets no Cloudflare R2.
Eu: “Como disparo o processamento quando arquivos chegam?”
Claude: Explica arquitetura orientada a eventos: R2 → Queue → Worker → VPS
Eu: “Crie um PRD para implementar tudo isso”
Claude: Gera PRD completo com mais de 2000 palavras, 8 tasks, mais de 30 subtasks
📄 Baixe o PRD completo gerado aqui.
A arquitetura: de simples para sofisticada
Antes: armazenamento de arquivo local
┌─────────────┐
│ Download B3 │
└──────┬──────┘
│
▼
┌─────────────┐
│ Arquivo │
│ Local │
│ /tmp/*.csv │
└──────┬──────┘
│
▼
┌─────────────┐
│ Processar │
│ Manualmente │
└──────┬──────┘
│
▼
┌─────────────┐
│ PostgreSQL │
└─────────────┘
Problemas:
- Ponto único de falha
- Sem backup
- Execução manual
- Difícil debugar problemas
Depois: cloud-native orientado a eventos
┌─────────────┐
│ Download B3 │
└──────┬──────┘
│
▼
┌──────────────────────┐
│ Cloudflare R2 │
│ financial-data/ │
│ └─ b3/ │
│ └─ instruments/│
│ └─ YYYY-MM- │
│ DD.csv │
└──────┬───────────────┘
│
│ (Evento: object-create)
▼
┌──────────────────────┐
│ Cloudflare Queue │
│ b3-upload-events │
└──────┬───────────────┘
│
▼
┌──────────────────────┐
│ Cloudflare Worker │
│ (Event Handler) │
└──────┬───────────────┘
│
│ (HTTP POST)
▼
┌──────────────────────┐
│ VPS Webhook │
│ /webhooks/r2/upload │
└──────┬───────────────┘
│
▼
┌──────────────────────┐
│ Background Job │
│ Download & Process │
└──────┬───────────────┘
│
▼
┌──────────────────────┐
│ PostgreSQL │
│ (Dados Processados) │
└──────────────────────┘
Benefícios:
- Backups automáticos (durabilidade de 11 noves do R2)
- Processamento orientado a eventos (sem cron jobs)
- Trilha de auditoria (quem enviou o quê, quando)
- Escalável para múltiplas fontes de dados
- Colaboração em equipe (bucket compartilhado)
Implementação: abordagem task por task
O PRD dividiu o trabalho em 8 tasks principais com mais de 30 subtasks. Cada subtask = um commit atômico.
Task 1: Setup do ambiente
O que fizemos:
- Criamos
.env.examplecom todas as variáveis de configuração - Configuramos MinIO (emulador compatível com S3) para desenvolvimento local
- Configuramos Docker Compose para ambiente de desenvolvimento reproduzível
Por Que MinIO?
Durante o desenvolvimento, não queremos ficar batendo no Cloudflare R2 constantemente. MinIO fornece uma API S3-compatible local que se comporta identicamente ao R2.
# docker-compose.yml
version: '3.8'
services:
minio:
image: minio/minio:latest
ports:
- "9000:9000" # API
- "9001:9001" # Console
environment:
MINIO_ROOT_USER: minioadmin
MINIO_ROOT_PASSWORD: minioadmin123
command: server /data --console-address ":9001"
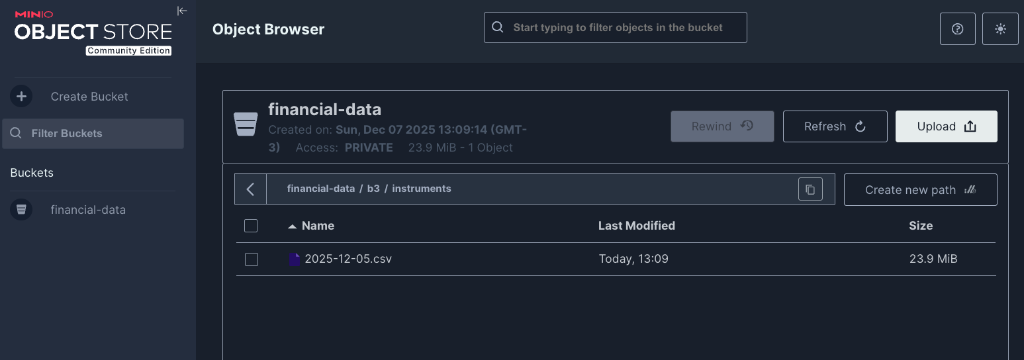 Console do MinIO rodando localmente com nosso bucket de dados.
Console do MinIO rodando localmente com nosso bucket de dados.
Workflow de desenvolvimento:
# Iniciar emulador local de R2
docker-compose up -d
# Executar pipeline (bate no MinIO)
ENVIRONMENT=development python scripts/download_b3.py
# Verificar no console do MinIO
open http://localhost:9001
Task 2: Camada de abstração de storage
Criamos uma classe StorageManager que abstrai todas as operações do R2:
Decisão chave de design: Suportar tanto local (MinIO) quanto produção (R2) sem mudanças de código.
# Detecta automaticamente o ambiente
manager = StorageManager()
# Mesmo código funciona localmente e em produção
manager.upload_instrument_file(local_path, date)
Troca de ambiente:
# Desenvolvimento local
ENVIRONMENT=development python script.py # → MinIO
# Produção
ENVIRONMENT=production python script.py # → Cloudflare R2
Este padrão nos poupou incontáveis bugs. Pudemos testar tudo localmente antes de tocar em produção.
Task 3: Padronização de nomes de arquivo
Nomeação antiga: O que quer que a B3 nos desse (InstrumentsConsolidatedFile_20241119_1.csv)
Nomeação nova: YYYY-MM-DD.csv
Por que padronizar?
- Queries de range de data fáceis: “Me dê todos os arquivos de novembro”
- Paths previsíveis:
b3/instruments/2024-11-19.csv - Lógica de sobrescrita simples: Mesma data = sobrescrever
- Compatível com ISO 8601 (ordenável alfabeticamente)
def get_standardized_filename(date: datetime) -> str:
"""Converte data para nome de arquivo padronizado."""
return f"{date.strftime('%Y-%m-%d')}.csv"
# 2024-11-19 → 2024-11-19.csv
# 2025-01-05 → 2025-01-05.csv
Na interface do MinIO (que espelha o R2), podemos ver claramente a organização dos arquivos com a nova padronização, facilitando a inspeção visual e programática.
Task 4: Processamento orientado a eventos
Aqui as coisas ficam sofisticadas. Em vez de cron jobs verificando “há um arquivo novo?”, deixamos o R2 nos avisar.
Passos de configuração no Cloudflare:
-
Criar uma Queue: Criamos uma fila chamada
b3-instruments-upload-queueno painel do Cloudflare Queues. Esta fila atua como um buffer resiliente para receber os eventos. - Configurar Event Notification no R2:
No bucket
financial-data, configuramos uma regra de notificação:- Evento:
object-create(apenas uploads) - Prefixo:
b3/instruments/(apenas pasta de instrumentos) - Destino: A queue que criamos anteriormente.
- Evento:
- Deploy do Cloudflare Worker:
// workers/r2-event-handler.js
export default {
async queue(batch, env) {
for (const message of batch.messages) {
const { bucket, key, size } = message.body;
// Chamar webhook da VPS
await fetch('https://my-vps.com/webhooks/r2/upload', {
method: 'POST',
headers: { 'Content-Type': 'application/json' },
body: JSON.stringify({
event_type: 'b3_instrument_uploaded',
bucket,
key,
size,
timestamp: new Date().toISOString()
})
});
message.ack();
}
}
}
O fluxo:
- Upload de arquivo para R2 → Evento dispara
- Evento vai para Queue → Worker processa
- Worker chama VPS → Background job disparado
- Job baixa do R2 → Processa dados
- Salva no PostgreSQL → Deleta arquivo temp do R2
Por que isso é melhor que polling:
- Instantâneo: Processamento começa imediatamente
- Econômico: Sem chamadas de API desperdiçadas verificando arquivos
- Escalável: Pode lidar com bursts (múltiplos arquivos enviados)
- Confiável: Queue garante entrega mesmo se VPS estiver offline
A estratégia Git: commits permitindo rollback
Cada subtask resultou em um commit com mensagem semântica (Conventional Commits). Isso mantém o histórico limpo e auditável:
feat(storage): implementa upload R2 com lógica de retry
feat(config): adiciona detecção de ambiente para local/prod
test(integration): adiciona testes de conexão MinIO
docs: atualiza README com guia de integração R2
Se algo quebrar em produção, podemos fazer rollback cirúrgico de apenas um commit específico (git revert abc123), sem precisar desfazer a feature inteira.
Análise de custos: o que realmente estamos pagando
Vamos detalhar os custos reais (não teóricos):
Uso Atual (Mês 1)
- Storage: Aproximadamente 1.5 GB (30 dias × 50MB arquivos)
- Operações Class A: Aproximadamente 60 (30 uploads + 30 downloads)
- Operações Class B: Aproximadamente 30 (operações de listagem)
Custos Cloudflare R2
Free Tier (estamos bem dentro disso):
- 10 GB storage/mês
- 1 milhão de operações Class A
- 10 milhões de operações Class B
O que pagamos: $0.00/mês
Cloudflare Queues:
- 10 milhões de operações/mês grátis
- Usamos: aproximadamente 30/mês
O que pagamos: $0.00/mês
Cloudflare Workers:
- 100.000 requests/dia grátis
- Usamos: aproximadamente 30/mês
O que pagamos: $0.00/mês
Custo mensal total: $0.00
Mesmo se escalarmos 100x (3.000 arquivos/mês), ainda estaríamos confortavelmente no free tier.
Desenvolvimento local: a vantagem do MinIO
Uma de nossas melhores decisões foi usar MinIO para desenvolvimento local.
Tempo de setup: 5 minutos
Custo: $0 (roda localmente)
Compatibilidade com R2: 99.9%
Nosso loop de desenvolvimento:
# Terminal 1: Iniciar MinIO
docker-compose up minio
# Terminal 2: Executar pipeline
python scripts/download_b3.py --date 2024-12-05
# Terminal 3: Verificar o que foi enviado
aws s3 ls s3://financial-data/b3/instruments/ \
--endpoint-url http://localhost:9000
[Split Terminal]: Usar terminais divididos permite ver o log do servidor MinIO e a execução do nosso script simultaneamente, garantindo feedback imediato.
Estratégia de testes: 5 de dezembro de 2025
Escolhemos uma data específica de teste: 5 de dezembro de 2025 (uma data futura no momento da escrita).
Por que uma data futura?
- Testa nossa lógica de handling de datas
- Garante que não há suposições de data hardcoded
- Valida que o pipeline funciona para qualquer data
Checklist de teste:
- Download da B3 para 2025-12-05
- Upload para MinIO como
2024-12-05.csv - Arquivo aparece no path correto:
b3/instruments/2024-12-05.csv - Tamanho do arquivo maior que 0 bytes
- Encoding CSV é cp1252 (formato da B3)
- Pode baixar arquivo de volta do MinIO
- Sobrescrita funciona (re-executar mesma data)
- Processamento disparado (em produção)
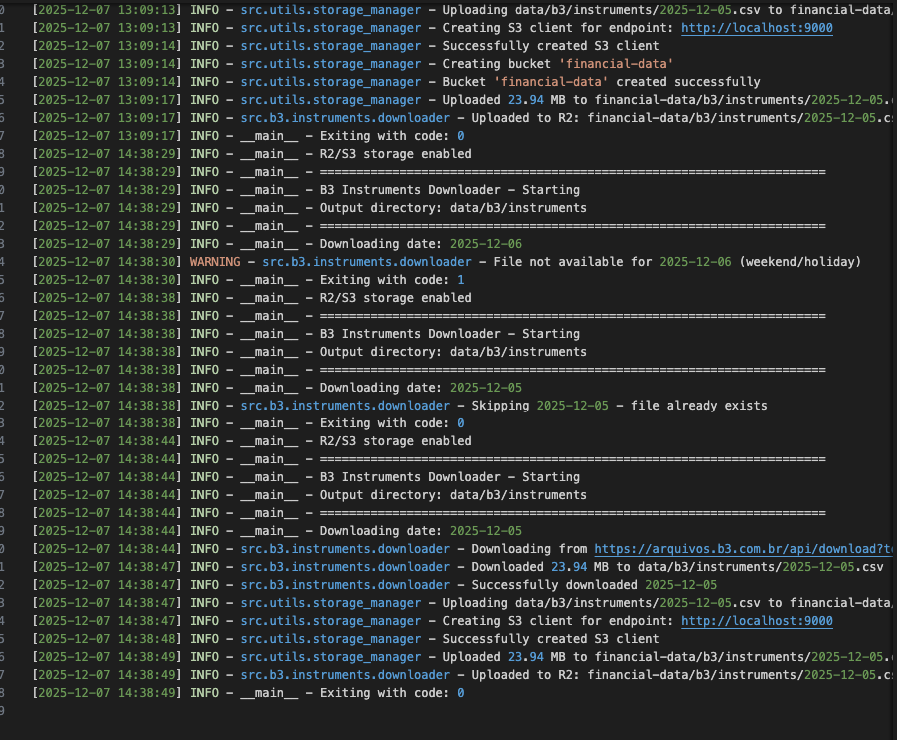 Sucesso no download da B3 e upload imediato para o Storage Manager.
Sucesso no download da B3 e upload imediato para o Storage Manager.
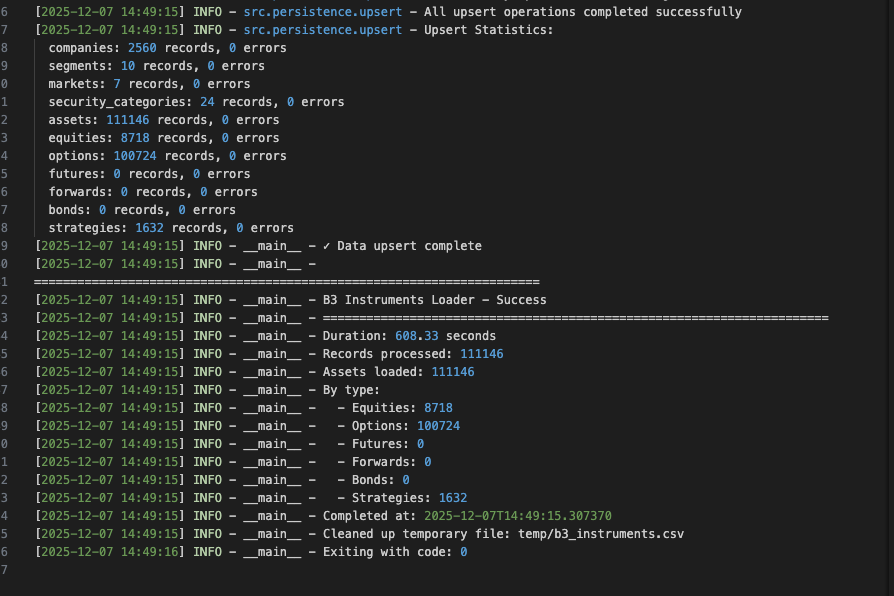 Pipeline completo executado com sucesso: ingestão, processamento e carga no banco.
Pipeline completo executado com sucesso: ingestão, processamento e carga no banco.
Deploy em produção: o momento da verdade
Checklist pré-deploy:
# 1. Variáveis de ambiente configuradas
echo $R2_ACCESS_KEY_ID
echo $R2_SECRET_ACCESS_KEY
echo $R2_ENDPOINT
# 2. Bucket existe
aws s3 ls s3://financial-data --endpoint-url $R2_ENDPOINT
# 3. Event notification configurada
# (Verificação manual no dashboard Cloudflare)
# 4. Worker deployed
wrangler deploy
# 5. Endpoint de webhook da VPS pronto
curl -X POST https://my-vps.com/webhooks/r2/upload -d '{}'
Primeira execução em produção:
# Trocar para produção
export ENVIRONMENT=production
# Executar para data de hoje
python scripts/download_b3.py
# Verificar dashboard Cloudflare
Funcionou na primeira tentativa.
Por quê? Porque testamos tudo localmente primeiro com MinIO, simulando o ambiente real quase perfeitamente.
Lições aprendidas: o que funcionou e o que não funcionou
O que funcionou muito bem
1. PRD gerado com assistência
Ter o Claude criando o PRD nos poupou aproximadamente 8 horas de planejamento. A divisão de tasks estava quase perfeita, necessitando apenas ajustes menores.
2. MinIO para desenvolvimento local
Poder testar tudo localmente antes de tocar em produção foi inestimável. Pegamos 3 bugs que teriam sido desastres em produção.
3. Commits atômicos
A estratégia de um-commit-por-subtask tornou code review trivial e nos deu capacidade de rollback cirúrgico.
4. Arquitetura orientada a eventos
Sem mais cron jobs. O pipeline agora é verdadeiramente reativo. Upload de arquivo → processamento começa automaticamente.
5. Nomeação padronizada
YYYY-MM-DD.csv torna tudo previsível. Sem mais parsing de nomes de arquivo estranhos.
O que faríamos diferente
1. Começar com .env.example
Deveríamos ter criado .env.example antes de escrever qualquer código. Acabamos fazendo engenharia reversa dele a partir do nosso .env funcional.
2. Adicionar lógica de retry mais cedo
Nossa primeira versão não fazia retry de uploads falhados. Adicionamos na Task 3, mas deveria ter sido incluído desde o dia um.
3. Logging mais granular
Adicionamos logging conforme fomos. Deveríamos ter configurado structured logging (JSON) desde o início para melhor debugging.
4. Setup de monitoramento de custos
Mesmo estando no free tier, deveríamos ter configurado alertas de billing do Cloudflare desde o dia um.
Os números: impacto do refactoring
Tempo de desenvolvimento
- Geração do PRD (com Claude): 1 hora
- Setup Local (MinIO): 30 minutos
- Implementação de Código: 8 horas
- Testes: 2 horas
- Documentação: 2 horas
- Total: aproximadamente 14 horas
Mudanças de código
- Arquivos modificados: 3
- Arquivos criados: 6
- Linhas adicionadas: aproximadamente 450
- Linhas removidas: aproximadamente 50
- Mudança líquida: +400 linhas
Melhorias de confiabilidade
- Redundância de backup: 0% → 99.999999999%
- Automação de processamento: Manual → Orientado a eventos
- Colaboração em equipe: Impossível → Trivial
- Trilha de auditoria: Nenhuma → Completa
O que vem a seguir: escala para multi-source
Este refactoring não foi apenas sobre B3. É a fundação para nossa plataforma completa de dados do mercado financeiro brasileiro.
Adições futuras:
- ANBIMA: Debêntures, índices, dados de fundos
- CVM: Fundos imobiliários (FIIs), registros de empresas
- Consolidação: Dados mestres cross-source
A arquitetura escala trivialmente:
financial-data/
├── b3/
│ └── instruments/ # Concluído
├── anbima/
│ ├── debentures/ # Próximo
│ ├── funds/
│ └── indices/
└── cvm/
├── fiis/ # Em breve
└── companies/
Mesmo código, mesma infraestrutura. Apenas prefixos diferentes.
Recursos e código
Anexos: